|
eungyeuk (at) cs (dot) cmu (dot) edu I am a third-year PhD student in Computer Science Department at Carnegie Mellon University, advised by Prof. Zico Kolter. My research interest lies in data-centric ML for building robust and safe foundation models. I did my Master's studies at Korea Advanced Institute of Science and Technology (KAIST) under Prof. Jaegul Choo. Google Scholar / GitHub / CV / Twitter |

|
* indicates equal contribution
|
|
|
abstract /
paper
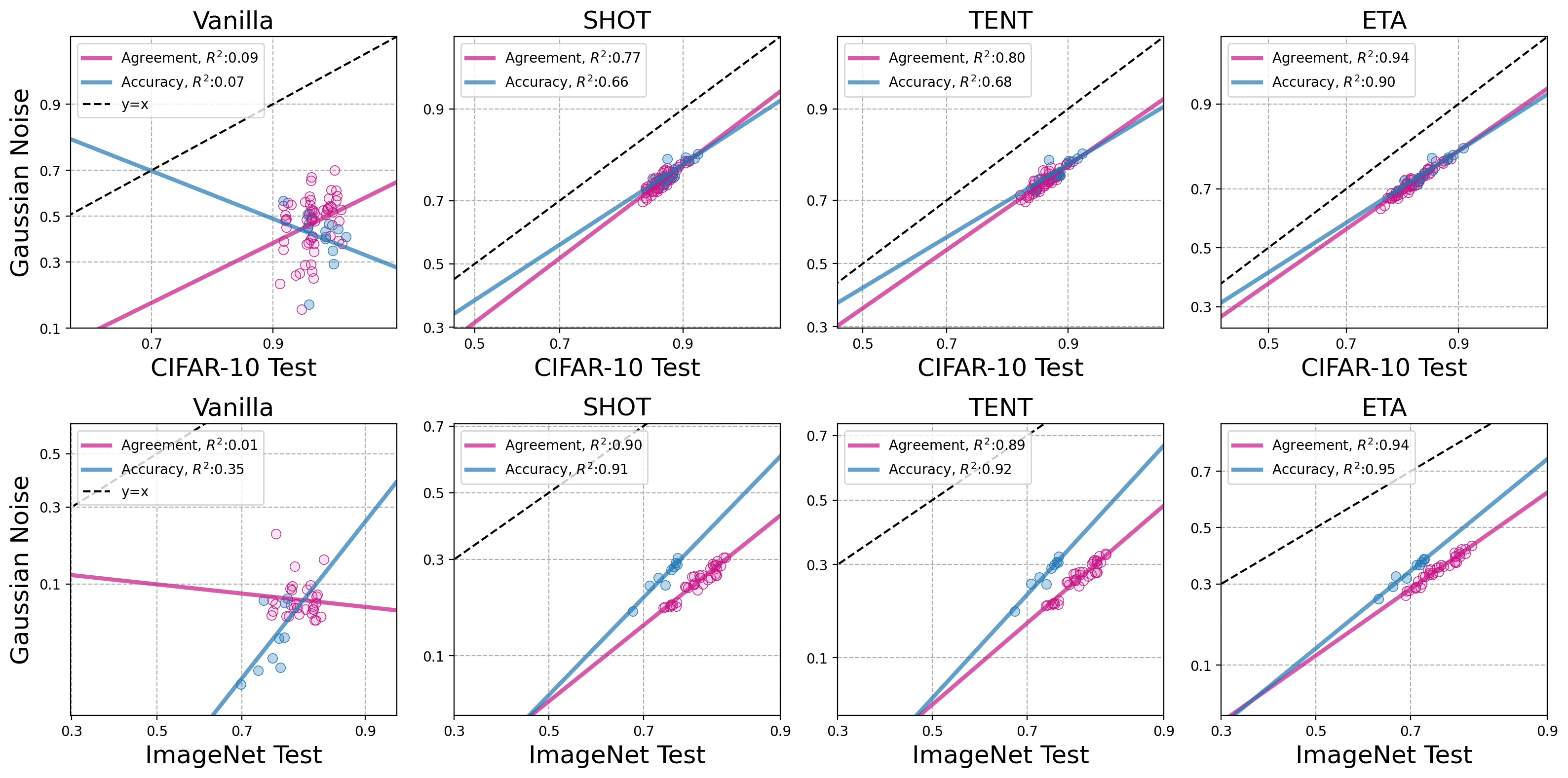
Recently, Miller et al. (2021) and Baek et al. (2022) empirically demonstrated strong linear correlations between in-distribution (ID) versus out-of-distribution (OOD) accuracy and agreement. These phenomena, termed accuracy-on-the-line (ACL) and agreement-on-the-line (AGL) furthermore often exhibited the same slope and bias of the correlations, enabling OOD model selection and performance estimation without labeled data. However, the phenomena also break for certain shift, such as CIFAR10-C Gaussian Noise, posing a critical bottleneck in accurately predicting OOD performance without access to labels. In this paper, we make a key finding that recent OOD test-time adaptation methods not only improve OOD performance, but drastically strengthen the AGL and ACL phenomenon, even in shifts that initially observed very weak correlations. To analyze this, we revisit the theoretical conditions established by Miller et al. (2021), which demonstrate that ACL appears if the distributions only shift in mean and covariance scale in Gaussian data. We find that these theoretical conditions hold when deep networks are adapted to CIFAR10-C data --- models embed the initial data distribution, with complex shifts, into those only with a singular ``scaling'' variable in the feature space. Building on these stronger linear trends, we demonstrate that combining TTA and AGL-based methods can predict the OOD performance with higher precision than previous methods for a broader set of distribution shifts. Furthermore, we discover that models adapted with different hyperparameters settings exhibit the same linear trends. This allows us to perform hyperparameter selection on OOD data without relying on any labeled data. |
|
abstract /
paper /
code /
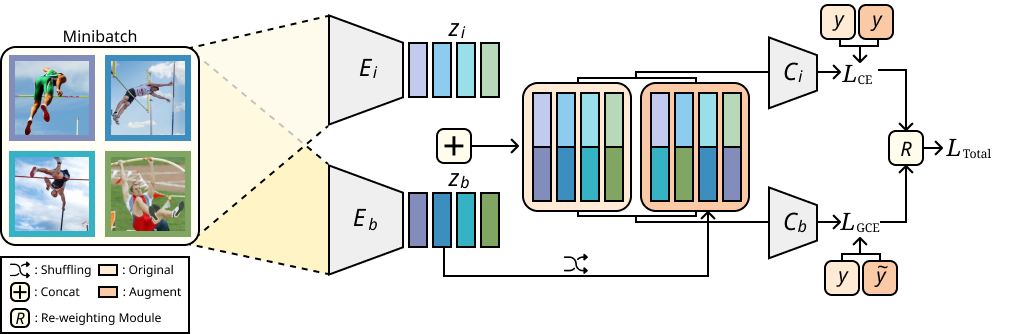
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as a real-world dataset. |

|
abstract /
paper /
project
Deep image colorization networks often suffer from the color-bleeding artifact, a problematic color spreading near the boundaries between adjacent objects. The color-bleeding artifacts debase the reality of generated outputs, limiting the applicability of colorization models on a practical application. Although previous approaches have tackled this problem in an automatic manner, they often generate imperfect outputs because their enhancements are available only in limited cases, such as having a high contrast of gray-scale value in an input image. Instead, leveraging user interactions would be a promising approach, since it can help the edge correction in the desired regions. In this paper, we propose a novel edge-enhancing framework for the regions of interest, by utilizing user scribbles that indicate where to enhance. Our method requires minimal user effort to obtain satisfactory enhancements. Experimental results on various datasets demonstrate that our interactive approach has outstanding performance in improving color-bleeding artifacts against the existing baselines. |
|
abstract /
paper
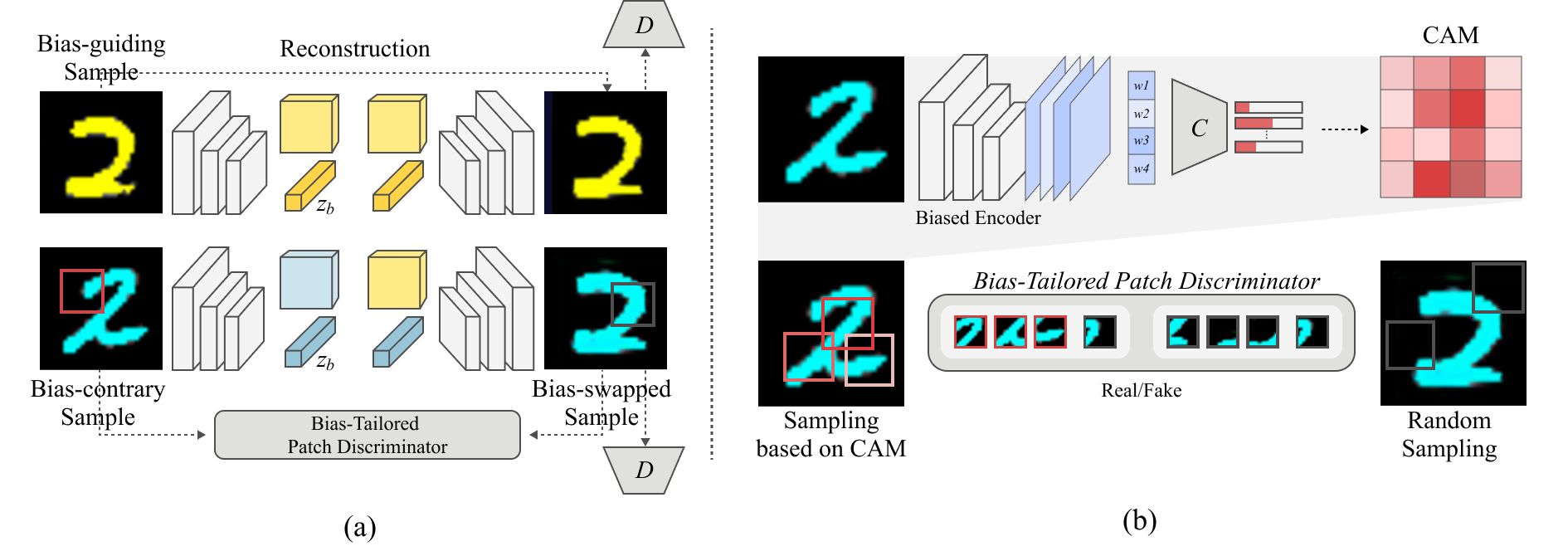
Deep neural networks often make decisions based on the spurious correlations inherent in the dataset, failing to generalize in an unbiased data distribution. Although previous approaches pre-define the type of dataset bias to prevent the network from learning it, recognizing the bias type in the real dataset is often prohibitive. This paper proposes a novel bias-tailored augmentation-based approach, BiaSwap, for learning debiased representation without requiring supervision on the bias type. Assuming that the bias corresponds to the easy-to-learn attributes, we sort the training images based on how much a biased classifier can exploits them as shortcut and divide them into bias-guiding and bias-contrary samples in an unsupervised manner. Afterwards, we integrate the style-transferring module of the image translation model with the class activation maps of such biased classifier, which enables to primarily transfer the bias attributes learned by the classifier. Therefore, given the pair of bias-guiding and bias-contrary, BiaSwap generates the bias-swapped image which contains the bias attributes from the bias-contrary images, while preserving bias-irrelevant ones in the bias-guiding images. Given such augmented images, BiaSwap demonstrates the superiority in debiasing against the existing baselines over both synthetic and real-world datasets. Even without careful supervision on the bias, BiaSwap achieves a remarkable performance on both unbiased and bias-guiding samples, implying the improved generalization capability of the model. |

|
abstract /
paper /
project /
video
This paper tackles the automatic colorization task of a sketch image given an already-colored reference image. Colorizing a sketch image is in high demand in comics, animation, and other content creation applications, but it suffers from information scarcity of a sketch image. To address this, a reference image can render the colorization process in a reliable and user-driven manner. However, it is difficult to prepare for a training data set that has a sufficient amount of semantically meaningful pairs of images as well as the ground truth for a colored image reflecting a given reference (e.g., coloring a sketch of an originally blue car given a reference green car). To tackle this challenge, we propose to utilize the identical image with geometric distortion as a virtual reference, which makes it possible to secure the ground truth for a colored output image. Furthermore, it naturally provides the ground truth for dense semantic correspondence, which we utilize in our internal attention mechanism for color transfer from reference to sketch input. We demonstrate the effectiveness of our approach in various types of sketch image colorization via quantitative as well as qualitative evaluation against existing methods.. |